
- 製品説明
-
NVIDIA RTX A400
NVIDIA RTX A400は、NVIDIA Ampere GPUアーキテクチャ上に構築されており、AIとレイトレーシングのアクセラレーションのパワーをより多くのプロフェッショナルの手にもたらします。6個の第2世代RTコア、24個の第3世代Tensorコア、768個のCUDAコア、そして4GBのGDDR6グラフィックメモリを搭載したRTX A400は、AIを活用したワークフローと見事なレイトレーシング映像を実現し、かつてないパフォーマンスを省スペース設計で提供します。
さらに、RTX A400は前世代よりもグラフィックスインターフェースが拡張され、最大4台のディスプレイを接続する事が可能となりました。そのコンパクトなフォームファクタにより、RTX A400はどんなワークステーションにも難なくフィットし、効率性や作業スペースを犠牲にすることなく、今日のプロフェッショナルなワークフローに必要な性能と機能を提供します。
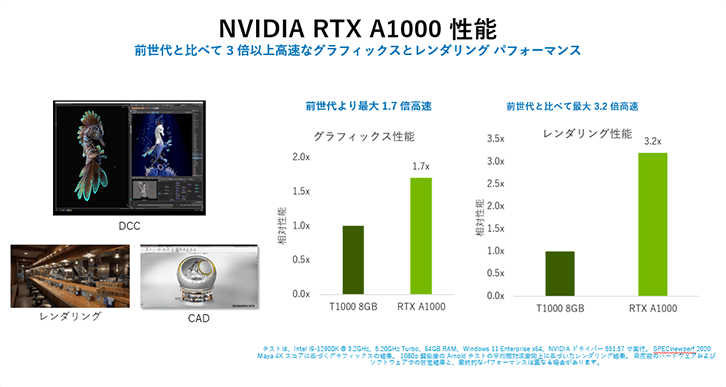
NVIDIA RTX A1000
NVIDIAは今回初めて、ロープロファイル、シングルスロットフォームファクタのGPUにRTコアを導入しました。1枚のRTX A1000ボードで、物理的に正確な影、反射、屈折を持つ複雑なプロフェッショナルモデルをレンダリングすることができ、ユーザーに瞬時の洞察を与えることができます。NVIDIA OptiX、Microsoft DXR、VulkanレイトレーシングなどのAPIを活用するアプリケーションと協調して動作することで、RTX A1000をベースとしたシステムは、これまでにないレベルの生産性を実現するための即時フィードバックを提供する、真にインタラクティブなデザインワークフローを強力にサポートします。RTX A1000は、前世代と比較してレンダリング性能が最大3倍高速化されています。このテクノロジーは、レイトレースされたモーションブラーのレンダリングも高速化し、より高いビジュアル精度でより高速な結果を実現します。
最新のワークフロー向けに開発されたRTX A1000は、Ampere GPUアーキテクチャの一部として強化されたTensorコアを搭載しており、前世代と比較して最大3倍のジェネレーティブAI性能を実現します。第3世代のTensorコアは、TF32およびBFloat16精度モードを加速します。浮動小数点と整数の独立したデータパスにより、計算とアドレス計算を混在させたワークロードをより効率的に実行する事が出来ます。
- 利用シーン
-
 3D デザインとビジュアライゼーション
3D デザインとビジュアライゼーション
- リアルタイムの結果が
リアルタイムでの意思決定を促進 - レイトレーシングとAIの広範な採用
 グラフィックデザインとビデオ制作
グラフィックデザインとビデオ制作
- レスポンシブな高解像度編集とエクスポート
- コンセプトから完成まで AI が支援
 Web ブラウジング
Web ブラウジング
- Web ページでの 3D の普及
- ビデオ中心のコンテンツ利用
 マルチ ディスプレイ
マルチ ディスプレイ
- どこからでも複数の高解像度ディスプレイを使用できる柔軟性
- AIによる低解像度ビデオコンテンツのアップレゾリューション
 チャットボットと LLM
チャットボットと LLM
- AI を活用したナレッジ検索
- ローカル LLM によるビジネス データのセキュリティ保証
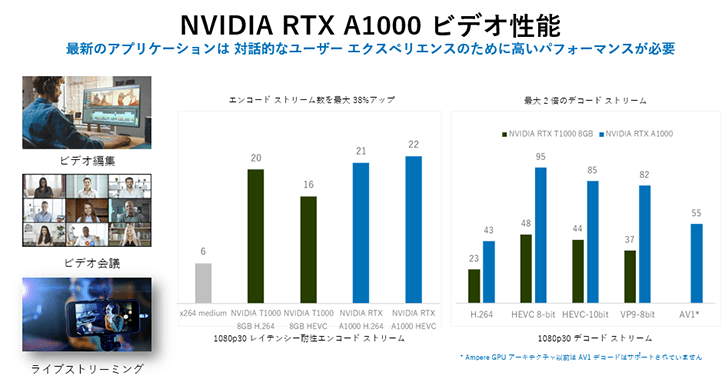
 ビデオ会議
ビデオ会議
- リアルタイムビデオのエンコードとデコード
- AIによるノイズ除去、顔追跡など
- リアルタイムの結果が
-
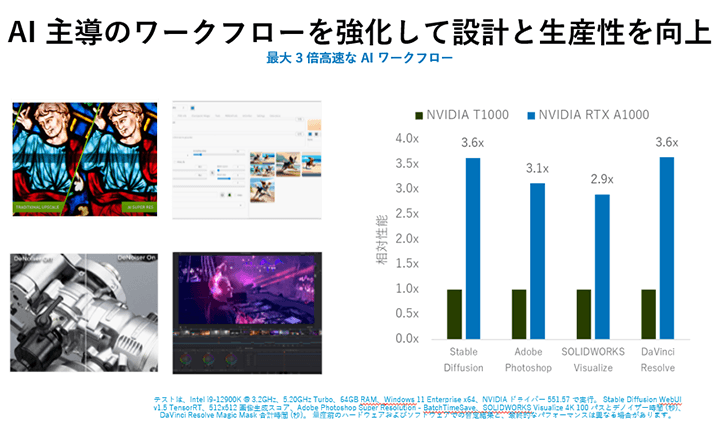
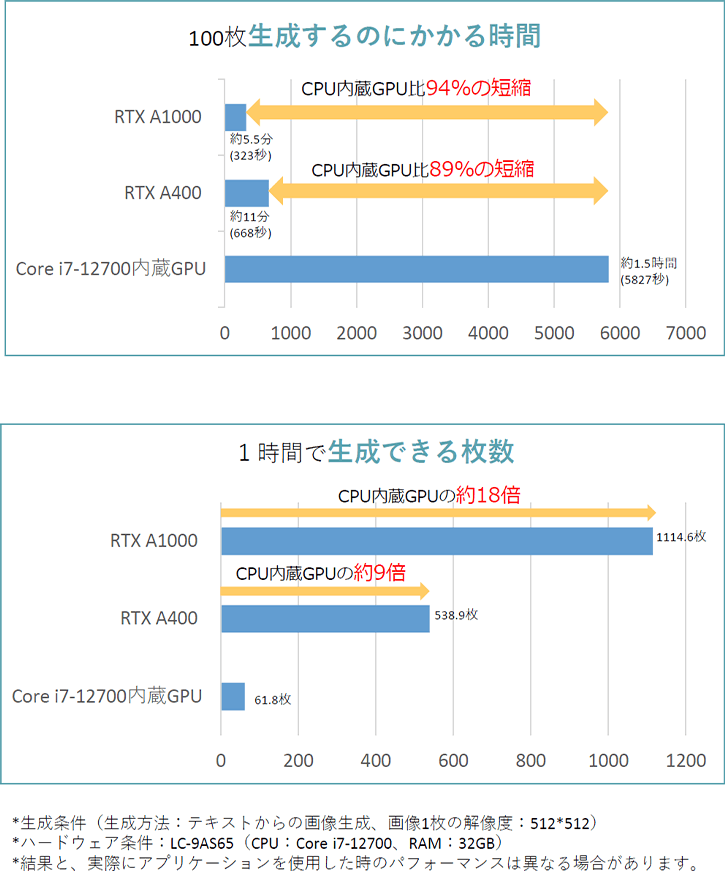
- AI処理ベンチマーク結果(テキストからの画像生成)
-
- 主な仕様
-
NVIDIA RTX A1000 NVIDIA RTX A400 GPUアーキテクチャ Ampere Ampere GPUメモリー 8GB GDDR6 4GB GDDR6 メモリーインターフェース 128bit 64bit メモリー帯域幅 192GB/s 96GB/s NVIDIA CUDAコア数 2,304 768 NVIDIA 第4世代 Tensorコア数 72 24 NVIDIA 第3世代 RTコア数 18 6 単精度演算性能(TFLOPS)※1 6.7 2.7 RTコア性能(TFLOPS)※1 13.2 5.3 Tensorコア FP16性能(TFLOPS)※2 53.8 21.7 Tensorコア ピーク INT8性能(TOPS)※3 107.8 43.3 システムインターフェース PCI Express 4.0 x8
(形状はx16)PCI Express 4.0 x8
(形状はx16)最大消費電力 50W 50W サーマルソリューション アクティブ アクティブ フォームファクター 2.7(H)×6.4(L) inch、
シングルスロット、
ロープロファイル2.7(H)×6.4(L) inch、
シングルスロット、
ロープロファイルディスプレイコネクター Mini DisplayPort 1.4a×4 Mini DisplayPort 1.4a×4 エンコード/デコードエンジン エンコード×1、デコード×2
(+AV1デコード)エンコード×1、デコード×1
(+AV1デコード)
※1 GPUブーストクロックに基づくピークレート
※2スパース機能を使用した実効FP16 テラ FLOPS
※3スパース性を備えたピーク INT8 TOPS
動作確認済み機種
- LC-9AS65
- LC-9AS63
- LC-9AR21
- LC-9AR21/XE
- LC-9ES65
- LC-9ER22
- LC-76S64
- LC-76S63
- LC-76S58
- LC-72A10
- LC-72S64
- LC-72S63
- LC-72S58
- LC-6DA10
- LC-6DS64
- LC-6DS63
- LC-6DS58
- LC-6EA10
- LC-5GS63
- LC-5GS64
- LC-9AR22
- LC-76M04
- LC-72M04
- LC-78M04
- LC-6FM04
- LC-6EM04
- LC-5GM04
- LC-9EM05
- LR-4CM05
- LR-36M04
- LR-36S58
- LR-36R21
- LR-4CS65
- LR-4CR21
- LR-4CR21/XE
- LR-4CR22